-
[회귀] 회귀모델Machine Learning/분류&회귀 2022. 8. 12. 23:57
회귀: 여러 개의 독립변수와 한 개의 종속변수 간의 상관관계를 모델링하는 기법
독립변수 개수 회귀 계수의 결합 1개 : 단일 회귀 선형: 선형 회귀 여러 개 : 다중 회귀 비선형 : 비선형 회귀 분류 => Category값(이산값) / 회귀 => Rrgression값(연속값)
- 릿지 : 선형 회귀에 L2 규제 추가한 회귀 모델
- 상대적으로 큰 회귀 계수 값의 예측 영향도를 감소시키기 위해 회귀 계수값을 더 작게 만드는 규제 모델
- W의 제곱에 패널티 부여
- 라쏘: 선형 회귀에 L1 규제 추가한 회귀 모델
- 예측 영향력이 작은 피청의 회귀 계수를 0으로 만듬
- W의 절댓값에 패널티 부여
- 엘라스틱넷: L2,L1 규제를 함께 결합한 모델
- L1 규제로 피처의 개수를 줄임과 동시에 L2 규제로 계수 값의 크기 조정
- 로지스틱 회귀: 매우 강력한 분류 알고리즘
- 이진 분류 뿐만 아니라 회귀 영역의 분류, 텍스트 분류와 같은 영역에서 뛰어난 예측 성능 보임
단순 선형 회귀: 독립변수 하나, 종속변수도 하나인 선형 회귀
ex) 주택 가격이 주택 크기로만 결정된다고 가정 -> 선형 관계
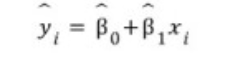
기울기 베타1과 절편 베타0를 회귀계수라 칭함(절편= intercept)
실제 주택 값을 구하게 되면 (b1*X + b0 +오류값) 오류값 더하거나 빼거나

- 실제 값과 회귀 모델 차이에 따른 오류 값을 잔차라고 부름
- 최적의 회귀 모델을 만든다는 것은 전체 데이터의 잔차(오류 값) 합이 최소가 되는 모델을 만드는 것 = 오류 값 합이 최소가 될 수 있는 최적의 회귀 계수를 찾는다
오류 값은 + 나 - 가 될 수 있음. 전체 데이터의 오류 합을 구하기 위해 단순 더했다가 의도치 않게 오류 합이 커질 수 있다. 따라서 절댓값을 취하거나, 제곱을 구해서 더하는 방식을 사용한다. 미분 등의 계산 편리 위해 Error의 제곱 = RSS을 빈번히 사용
=> RSS(오류의 제곱) 를 최소로 하는 B1,B0 회귀 계수를 학습을 통해 찾는 것이 머신러닝 기반 회귀의 핵심 사항
RSS는 비용(Cost)이며 회귀 계수로 구성되는 RSS를 비용함수(=손실 함수)라 함
오류의 값을 지속해서 감소시키고 최종적으로 더 이상 감소하지 않는 최소의 오류 값을 구함
실제 값과 예측값의 차이 최소화만 고려하다보면 학습 데이터에 지나치게 맞추게 되고, 회귀 계수가 쉽게 커짐
- 변동성이 오히려 심해져서 테스트 데이터 세트에서는 예측 성능 저하 우려
- RSS 최소화 방법과 과적합 방지를 위한 회귀 계수 값이 커지지 않도록 하는 방법이 서로 균형 이뤄야 함
- alpha 값을 크게 하면 비용 함수는 회귀 계수 W 값을 작게 해 과적합 개선할 수 있으며 alpha 값을 작게 하면 회귀 계수 W 값이 커져도 어느 정도 상쇄 가능해 학습 데이터 적합을 더 개선할 수 있음
비용 최소화 하기 - 경사하강법
: 오류 값이 더 이상 작아지지 않으면 그 오류 값을 최소 비용으로 판단하고 최적의 W값 파라미터 반환
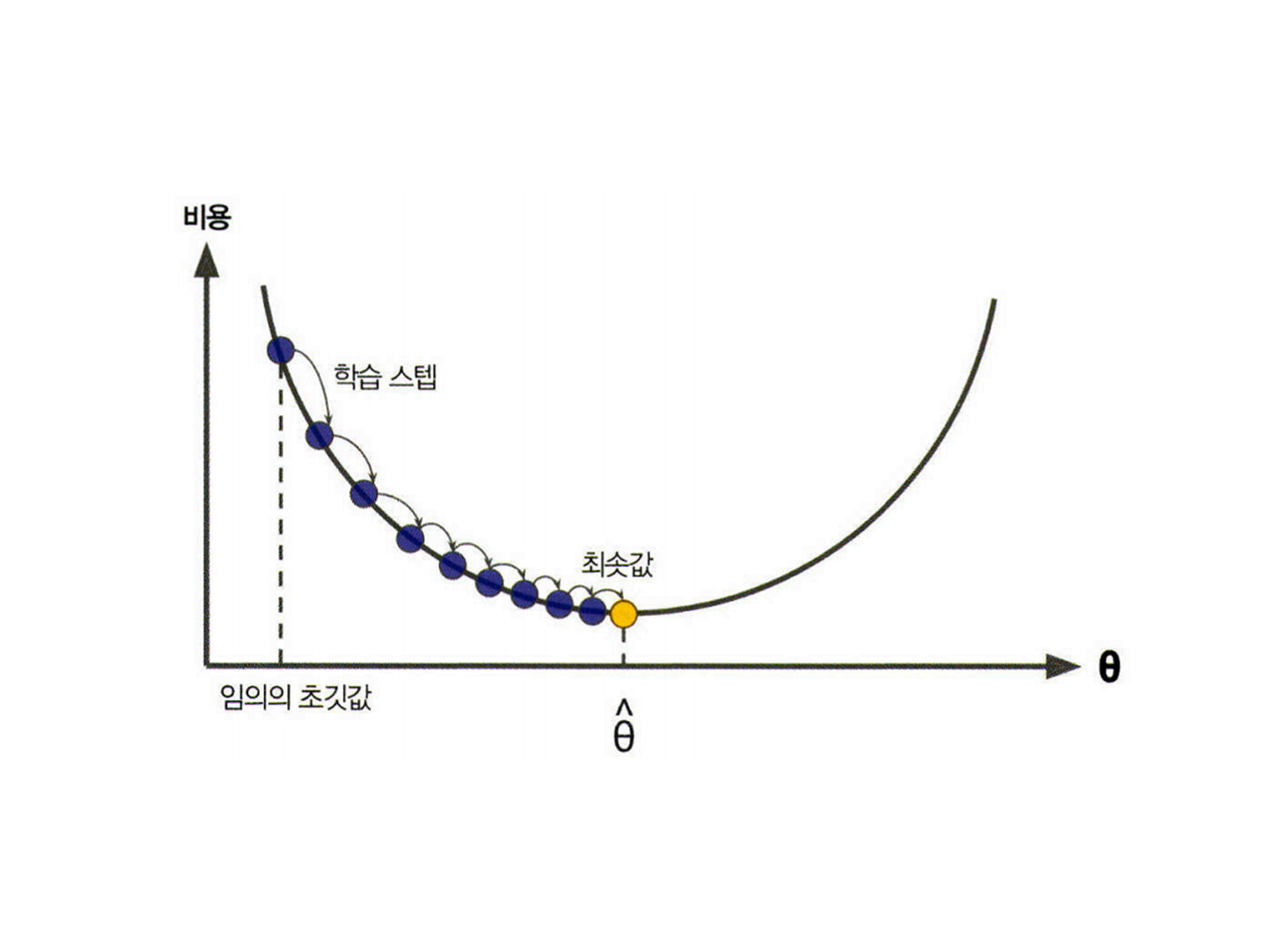
비용 함수 목표 = alpha 값을 크게 하면 비용 함수는 회귀 계수 w의 값을 작게 해 과적합을 개선할 수 있으며 alpha 값을 작게 하면 회귀 계수 W 값이 커져도 어느 정도 상쇄 가능하므로 학습 데이터 적합 더 개선 가능
선형 회귀 모델을 위한 데이터 변환
- 피처값과 타깃값의 분포가 정규분포 형태를 선호함
- 왜곡된 형태의 분포도일 경우 예측 성능에 부정적인 영향을 미칠 가능성이 높음
- 선형 회귀 모델 적용하기 전에 데이터 스케일링/정규화 작업 수행하는 것이 일반적
평가
- MAE: 실제값과 예측값의 차이를 절대값으로 변환해 평균한 것
- MSE(mean squared error): 실제값과 오차값의 차이를 제곱해 평균한 것
- RMSE(route mean squared error): MSE에 루트를 씌운 것(실제 오류 평균보다 커지는 것을 보정)
- R square : 분산 기반으로 예측 성능을 평가, 실제값의 분산 대비 예측값의 분산 비율을 지표로 함
- 1에 가까울수록 예측 정확도가 높음. 예측값 Variance / 실제값 Variance
회귀 평가 지표의 경우 값이 커지면 오히려 나쁜 모델이라는 의미
-1을 원래 평가 지표 값에 곱해 음수를 만들어 작은 오류값이 더 큰 숫자로 인식하게끔 함
ex) 10 > 1 => -1 > -10
반응형'Machine Learning > 분류&회귀' 카테고리의 다른 글
[회귀] 회귀모델_실습 (1) 2022.09.20 [회귀] 로지스틱 회귀 (0) 2022.08.17 [분류] 데이터 가공 후 결과 분석 (0) 2022.08.12 [분류] 분류기 정리 (0) 2022.08.12 [분류] 부스팅기법 (0) 2022.03.28 - 릿지 : 선형 회귀에 L2 규제 추가한 회귀 모델